resize()方法(初始化和扩容都是创建新的table)
解释为什么在新table的位置没有重新计算,而是根据(e.hash & oldCap) == 0,等于0就是在原位置,不等于0时,就是newtable[原位置+oldCap] ,如下图.
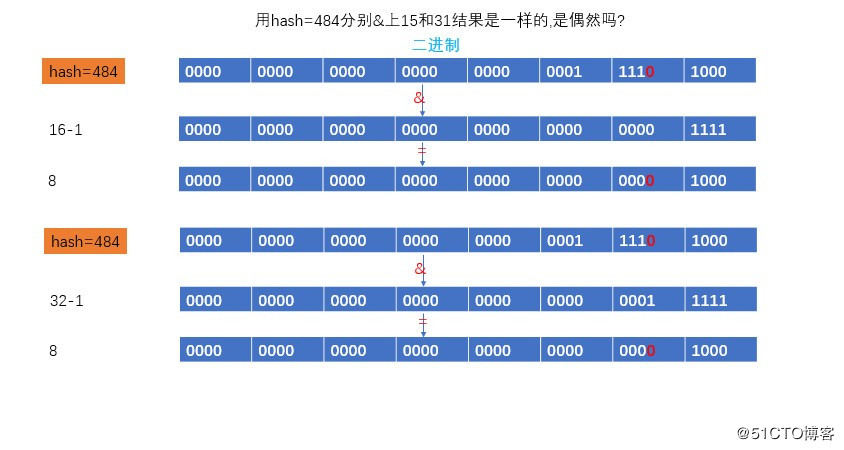
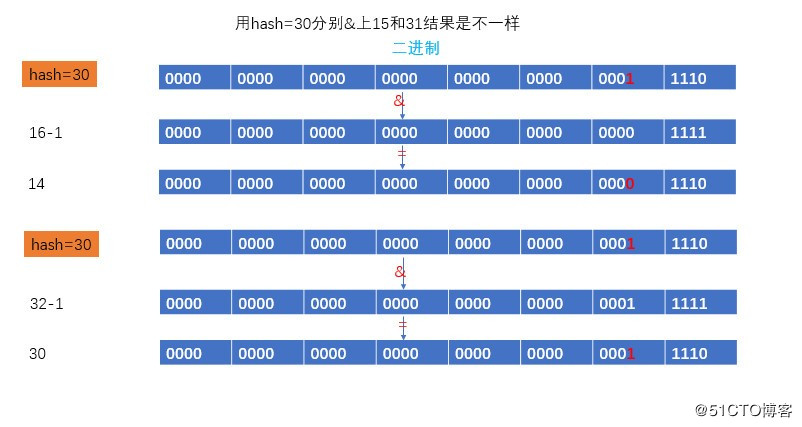
table长度我们以16为例,hash值我们以484和30为例,我们发现484&16=0,30&16=30,我们发现一个区别就是他们的他们的低5位一个是0,一个是1.
HashMap 源码浅析 1.8
 我们让低5位是0的484,分别&上(16-1)和(32-1),结论是位置没有发生变化,所以说如果低5位是0,那么扩容前和扩容后位置不变.
我们让低5位是0的484,分别&上(16-1)和(32-1),结论是位置没有发生变化,所以说如果低5位是0,那么扩容前和扩容后位置不变.
HashMap 源码浅析 1.8
 我们让低5位是1的30,分别&上(16-1)和(32-1),结论是位置发生变化,所以说如果低5位是1,那么新位置就是原来位置+oldCap.
我们让低5位是1的30,分别&上(16-1)和(32-1),结论是位置发生变化,所以说如果低5位是1,那么新位置就是原来位置+oldCap.
HashMap 源码浅析 1.8
其实我们发现(e.hash & oldCap) == 0 只是为了证明低5位是0还是1,这是为什么了,其实是和(16-1)和(32-1)有着密切的关系,15二进制是1111,31是11111,我们发现不管哪个数&上15或者31都是这个数低4位或者低5位本身,所以e.hash如果低5位0,那其实都是&1111,因为低5位是0&运算下还是0,如果e.hash的低5位是1,那么和0相比就是低5位会变成1,所以需要加上这个多的位置的值oldCap.
/**
* 扩容
* @return
*/
final Node<K,V>[] resize() {
// 旧table
Node<K,V>[] oldTab = table;
// 旧的table长度
int oldCap = (oldTab == null) ? 0 : oldTab.length;
// 旧的阈值
int oldThr = threshold;
int newCap, newThr = 0;
// 证明就table,已经被初始化了
if (oldCap > 0) {
// 如果旧的table大于做大值,阈值就设置为Internet的最大值,返回
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 给newCap赋值 newCap = oldCap << 1 (* 2^1) < MAXIMUM_CAPACITY(1 << 30)
// oldCap >= 16 证明已经初始化过了,现在是扩容(假如oldCap就是16)
// 新阈值 newThr = (oldThr = threshold) = 12 << 1(12 * 2^1)
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold // 新的阈值
}
// 这种情况是table还没有初始化
// oldThr >0 是因为在有参构造里面会把cap赋值给threshold
else if (oldThr > 0) // initial capacity was placed in threshold
// 容量就是oldThr
newCap = oldThr;
// 无参构造,容量和阈值都使用默认
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// newThr=0证明使用的是有参构造,容量有值,阈值没有值
// 所以初始化阈值
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
/** 上面属于table参数准备部分,分为初始化或者扩容 */
// 新的阈值
threshold = newThr;
// 创建新的table
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
// 开始遍历旧的table,进行数据迁移
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null; // 释放内存地址
if (e.next == null) // 表示只有一个元素
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode) // 如果是树结构,调用树结构的方法
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
// 链表结构的数据 lo 表示位置不变 hi表示位置是原来的位置+oldCap
// 是通过(e.hash & oldCap) == 0 这句话来判断的
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
// 解释在上面的图片
if ((e.hash & oldCap) == 0) {
if (loTail == null) // 第一次循环 tail 为null,所以头和尾都是 e
loHead = e; // 头部是当前的e
else // 接下来的循环tail不为null
loTail.next = e; // loTail 是上一次满足if的e
// e 是这一次满足if的e
// 所以loTail.next = e的目的就是,上一次满足if的e指向下一次满足if的e
// 代码就是loTail.next = e
loTail = e; // 每次循环尾部就是当前节点
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// 位置不变还是j
if (loTail != null) {
loTail.next = null; // 尾部节点的next设置为null
newTab[j] = loHead; // 设置头结点指向table[j] (第一次循环时,head=tail,接下来循环给tail追加节点)
}
// 位置变化,是 j+oldCap
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
节选:https://blog.51cto.com/14220760/2363572
微信扫描二维码,关注后回复,获取精华资料!
1、回复「书单」:免费获取百本「豆瓣」高分好书。
2、回复「赚钱」:领取实用的36个赚钱小项目。
3、回复「TED」:送你100场TED最受欢迎的演讲,感受最顶尖的思想。
4、回复「学习」:免费获赠英语7000单词速记法(价值200元,很好用),四六级轻松过;
5、回复「PPT」:送你500套好看又实用的PPT模板,让你的PPT颜值爆表]
6、回复「88」:java精品案例,微服务架构Springboot项目实战